

核心能力
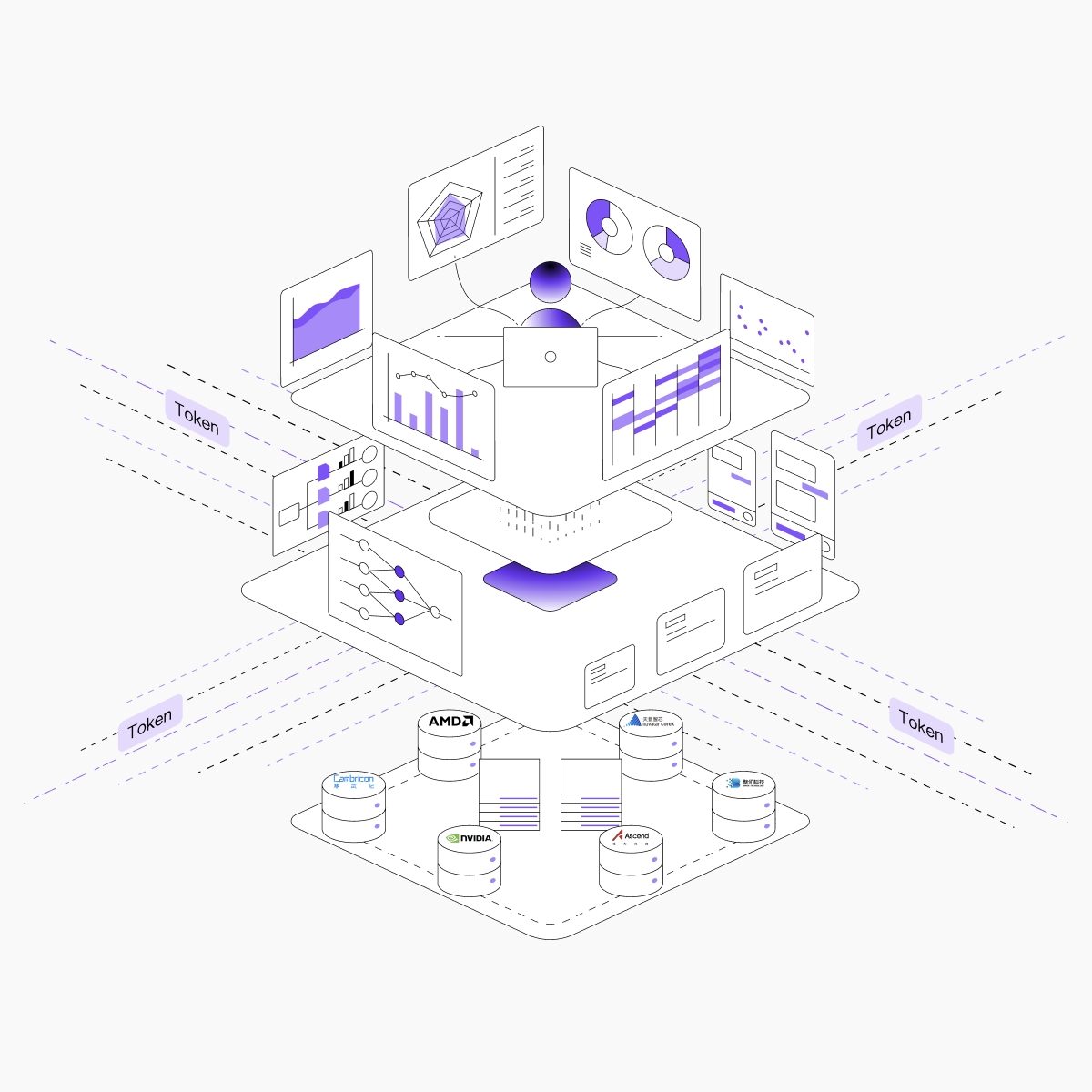
支持英伟达、AMD、华为昇腾、天数、沐曦、寒武纪、壁仞等多种主流AI芯片
自动池化管理与统一调度,屏蔽底层硬件差异
与上层负载调度深度集成优化,实现多种智能调度策略应用和资源高效利用
面向 AI 训练与推理的高性能存储与网络设计,满足多模态数据与大规模分布式计算的吞吐需求
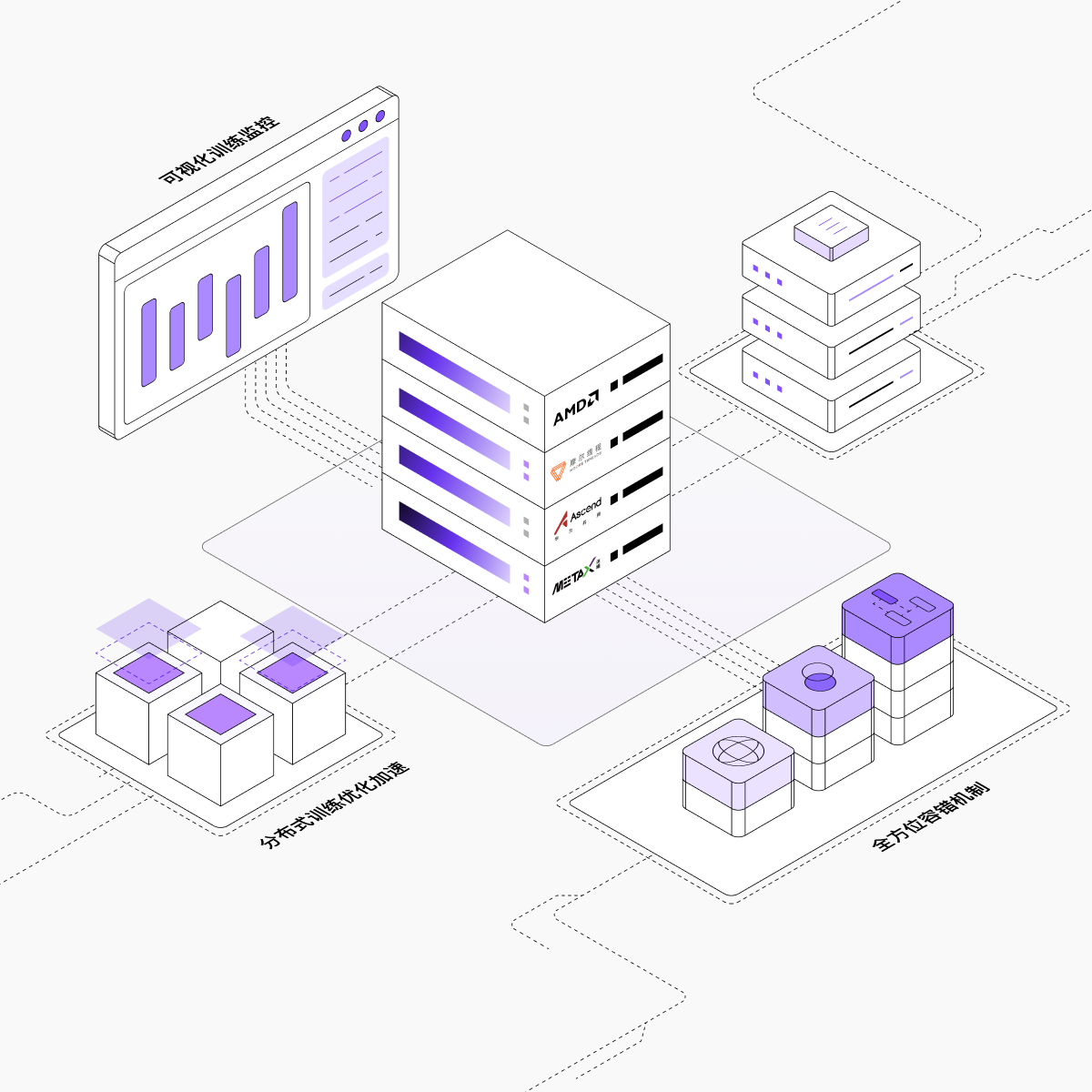
分布式训练优化加速:多节点协同计算的通信优化、通信拓扑自动优化、数据加载优化、启动时延降低
全方位容错机制:异步Checkpoint快速保存恢复,环境机器等多层级异常检测,分钟级任务恢复、迁移
可视化训练监控:实时指标追踪、训练过程可观测、异常自动告警
前沿算法原生支持:非侵入式支持强化学习、具身智能场景的基础设施
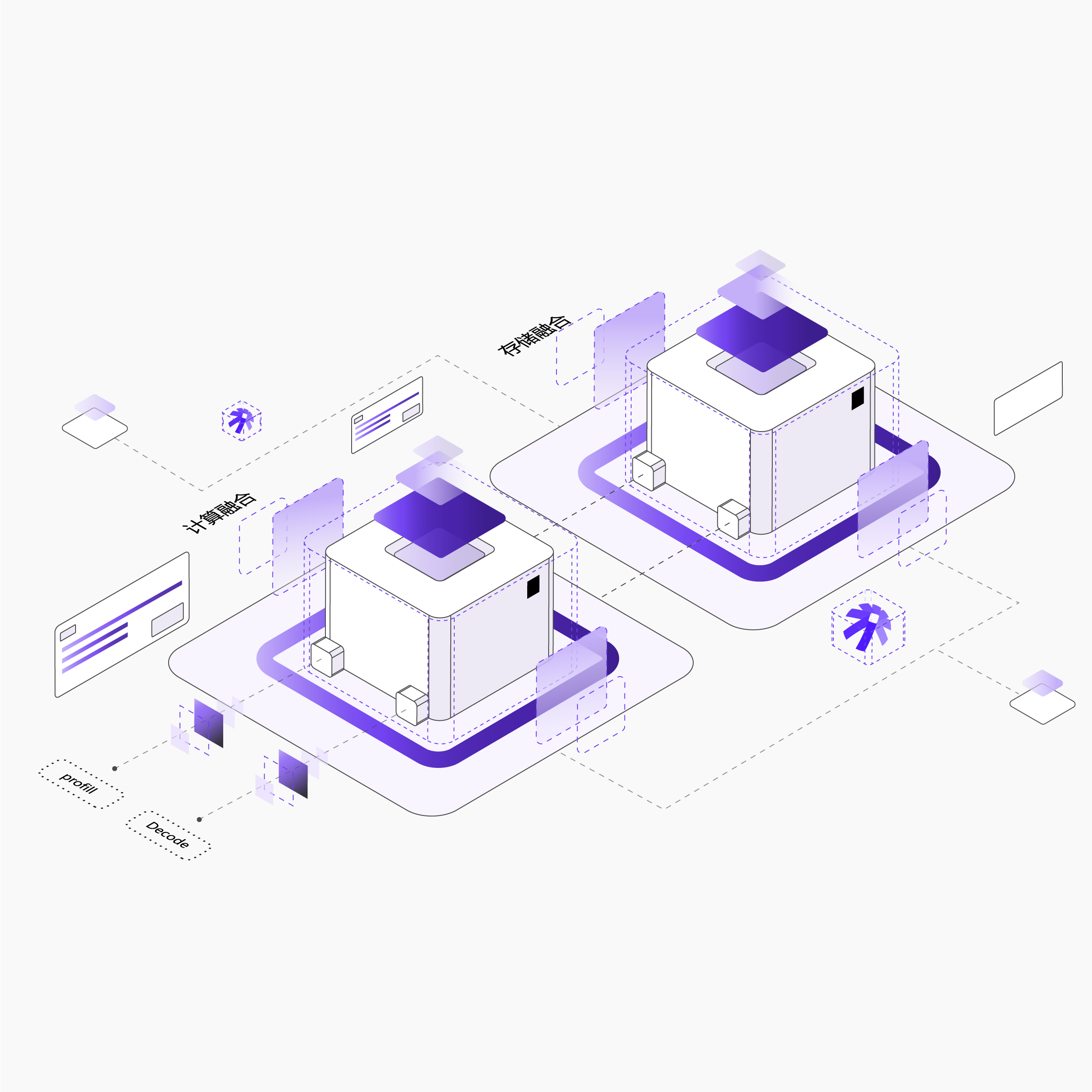
超大规模MOE集群推理:支持1T+参数超大模型的分布式推理一键拉起
Prefill-Decode分离架构支持:推理集群配置管理,支持多种长度文本生成场景的极致稳定性、性能优化
多模态AIGC优化:支持ComfyUI等多模态工作流的自动异步批量高并发处理,镜像存储缓存加速
弹性扩缩容:多种扩缩容策略支持,支持分钟级百实例弹性扩展,应对流量突发
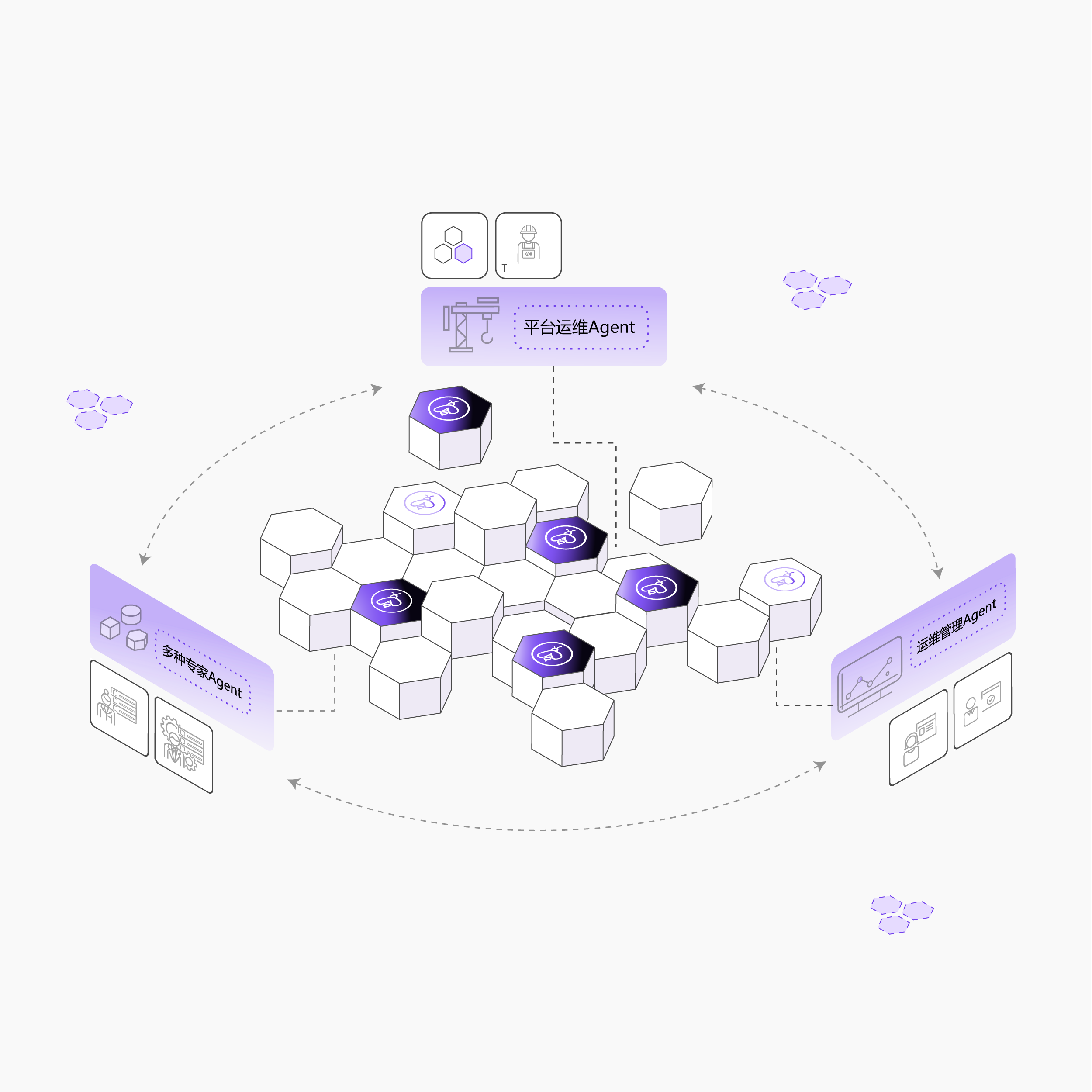
平台运维Agent:集群告警自动分析、异常检测处理、节点智能上下架
运营管理Agent:库存自动管理、负载与资源使用情况智能分析
多Agent协同:平台管家Agent协同资源管理助手、文档智能问答、训练排障等多种专家agent赋能
可靠支撑企业级大模型训练与推理全生命流程
高效构建、稳定运行、智能管理大规模AI基础设施
Agent全程护航,更快、更稳、更省
平台管家Agent
资源管理助手
文档智能问答
训练排障专家
运维Agent
集群告警处理
节点智能上下架
故障自动恢复
运营Agent
库存自动管理
SKU智能变更
活动价格调整
专家Agent 蜂群
多专家协同
智能决策
效率提升




为什么选择无问芯穹
客户故事

经常在 NCCL 60 分钟的超时阈值内难以完成,导致任务反复容错、训练无法顺利启动
几百B的模型MOE预训练和GRPO,60%-70%概率 2000卡任务跑1小时卡住,无法正常继续
可在15分钟内完成之前同样60分钟卡住的数据初始化问题
同样的训练任务可以正常吞吐稳定运行两周以上
若临时扩容需要等待1-2周从而错失业务流量,购买多余固定集群用于动态扩展的备用资源则会出现闲时的资源浪费,从而导致成本增加。
数据处理和模型训练使用不同的计算资源,工作环境割裂导致整个工作流复杂且难协同,产出物需要跨平台运输
基于平台实现了分钟级动态灵活的资源扩缩容,极大降低生产成本
训推一体,产出模型可以标准化方式快速嵌入到客户自有业务pipeline,模型更新迭代时间降低72%
释放无穹智能,让AGI触手可及
联系我们,获取定制化 AI 基础设施解决方案

