
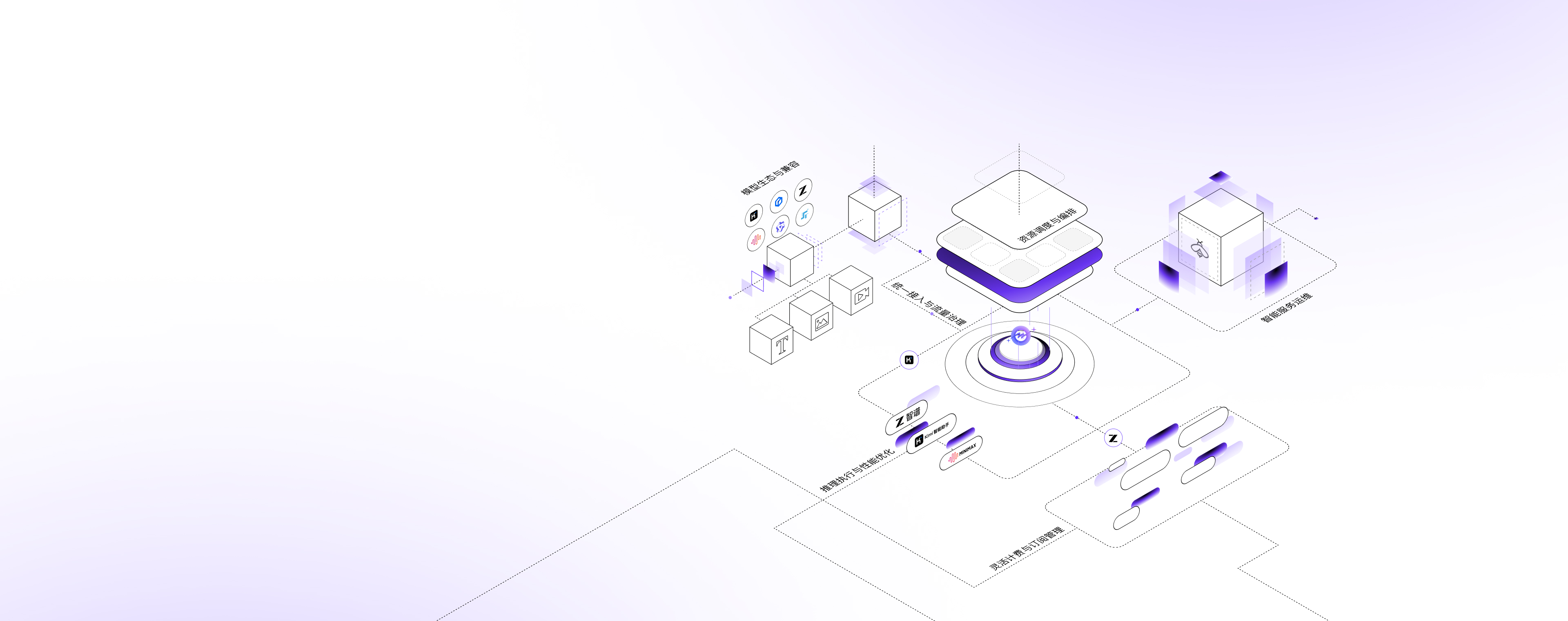
核心能力

提供广泛的模型支持与标准化接入能力,屏蔽底层差异,让开发者专注业务创新。
多模态模型全覆盖:支持包括大语言模型、图像理解、图像生成、视频生成、向量嵌入等多种维度的100+模型,满足丰富多样的应用场景
主流开源模型深度优化:针对DeepSeek、GLM、Kimi、Minimax、Qwen等主流开源模型提供高性能的服务优化
开发者友好的API兼容:完全兼容OpenAI与Anthropic API格式规范,满足多元化需求,零成本迁移
高阶复杂功能完备:支持工具调用(Function Calling)、结构化输出、流式返回等高级特性,可直接用于agent开发应用
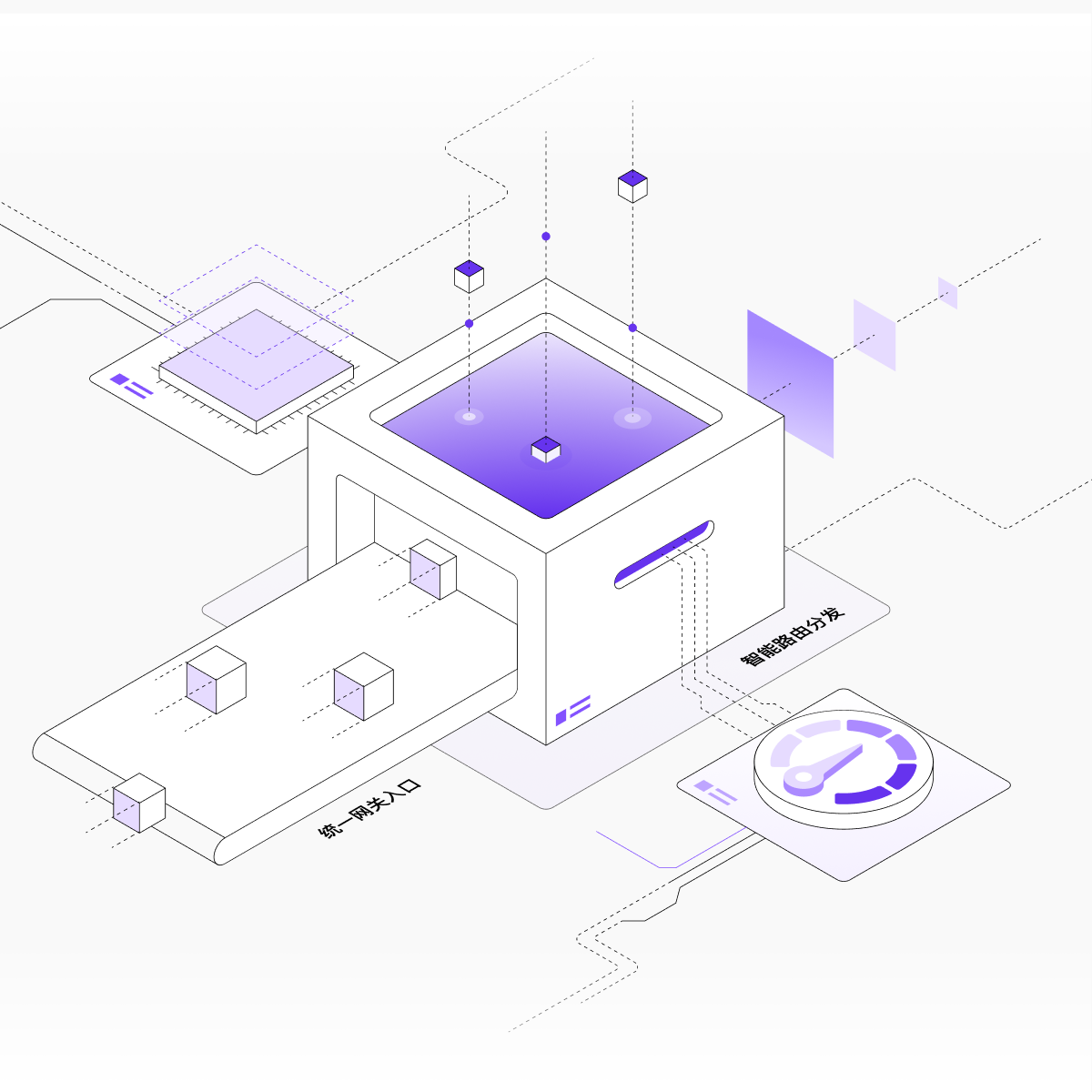
提供企业级的高可用架构,通过模型服务的统一入口与智能流量治理能力,保障多场景下的稳定服务与平滑升级、发布。
请求特征感知:统一网关入口自动识别请求类型、长度、复杂度等特征
智能路由与分发:根据请求特征分析智能分发请求到最优实例,支持Cache-aware路由
多种策略适配:支持按地域、用户、优先级、资源池等多维度的策略路由
流量治理与健康保护:支持秒级流量切换,一键回滚到稳定版本,并自动隔离问题实例
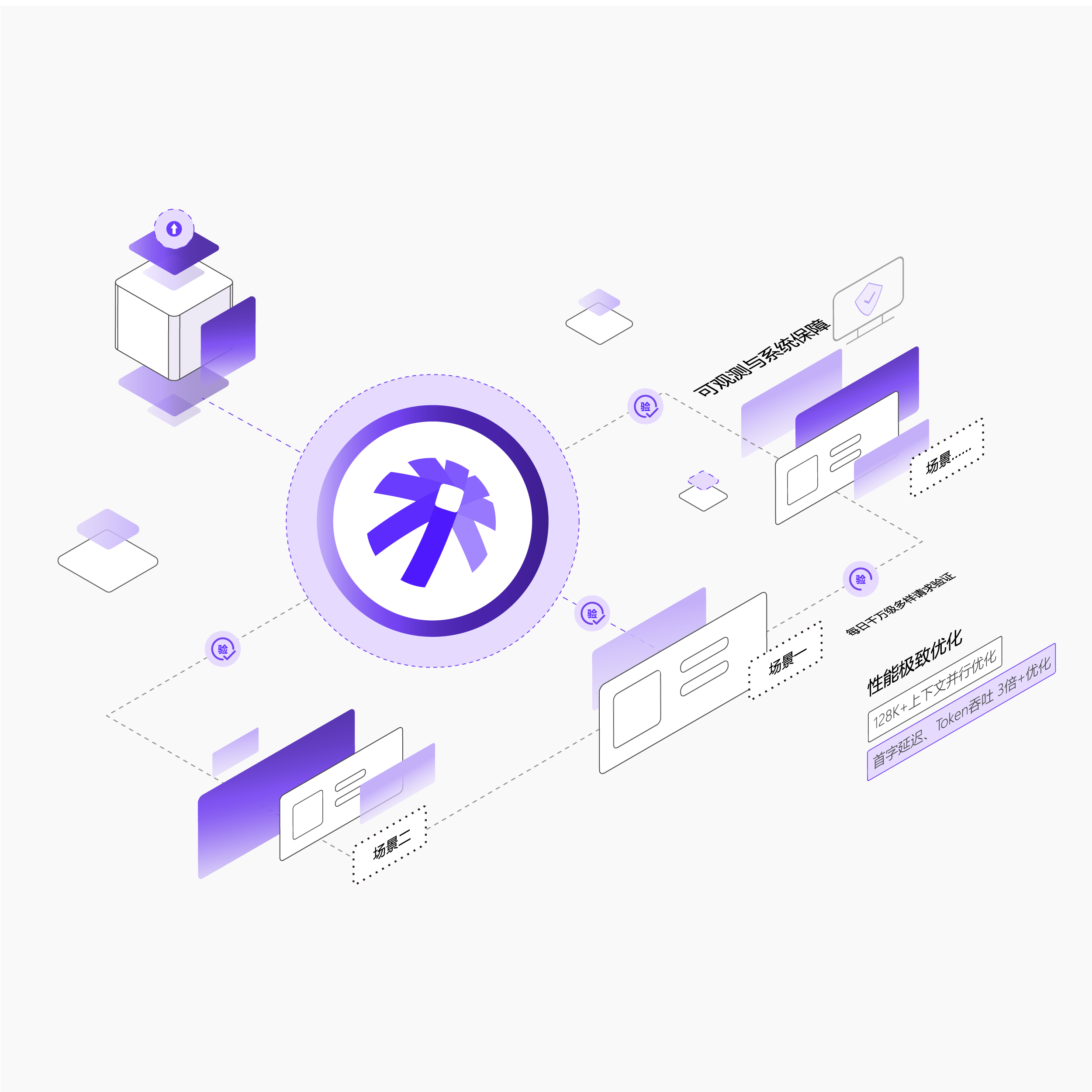
通过系统级工程优化,极致提升推理性能与资源利用效率,保障原厂级精度与用户体验。
高精度推理保障:支持超大规模模型的精确推理,工具调用、结构化输出等场景与原厂保持一致
极致性能优化:首字延迟、Token吞吐3倍以上优化,针对128K+上下文的专项序列并行优化
可观测与系统保障:支持实时性能监控与请求链路追踪,自动识别异常请求,定位性能瓶颈,提前发现问题
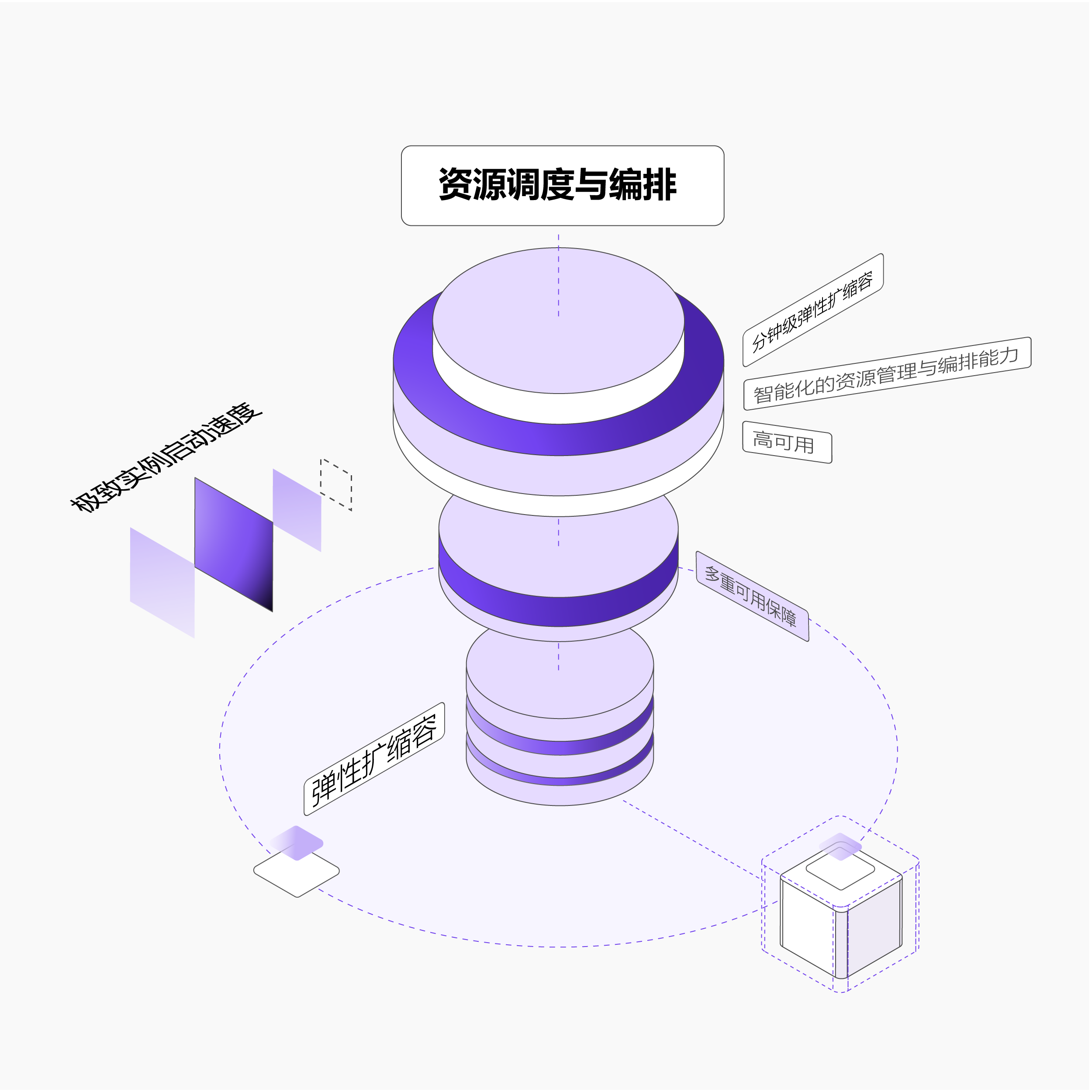
智能化的资源管理与编排能力,实现秒级启动,分钟级弹性扩缩容、快速交付与服务高可用。
业务感知的弹性扩缩容:基于真实业务负载自动调整实例数量,高峰期快速扩容满足业务需求
极致实例启动速度:基于模型缓存与容器镜像缓存,大幅度降低冷启动时间
多重可用保障:通过负载热迁移,跨AZ高可用架构,异常实例自动重启等方式保障服务持续高可用
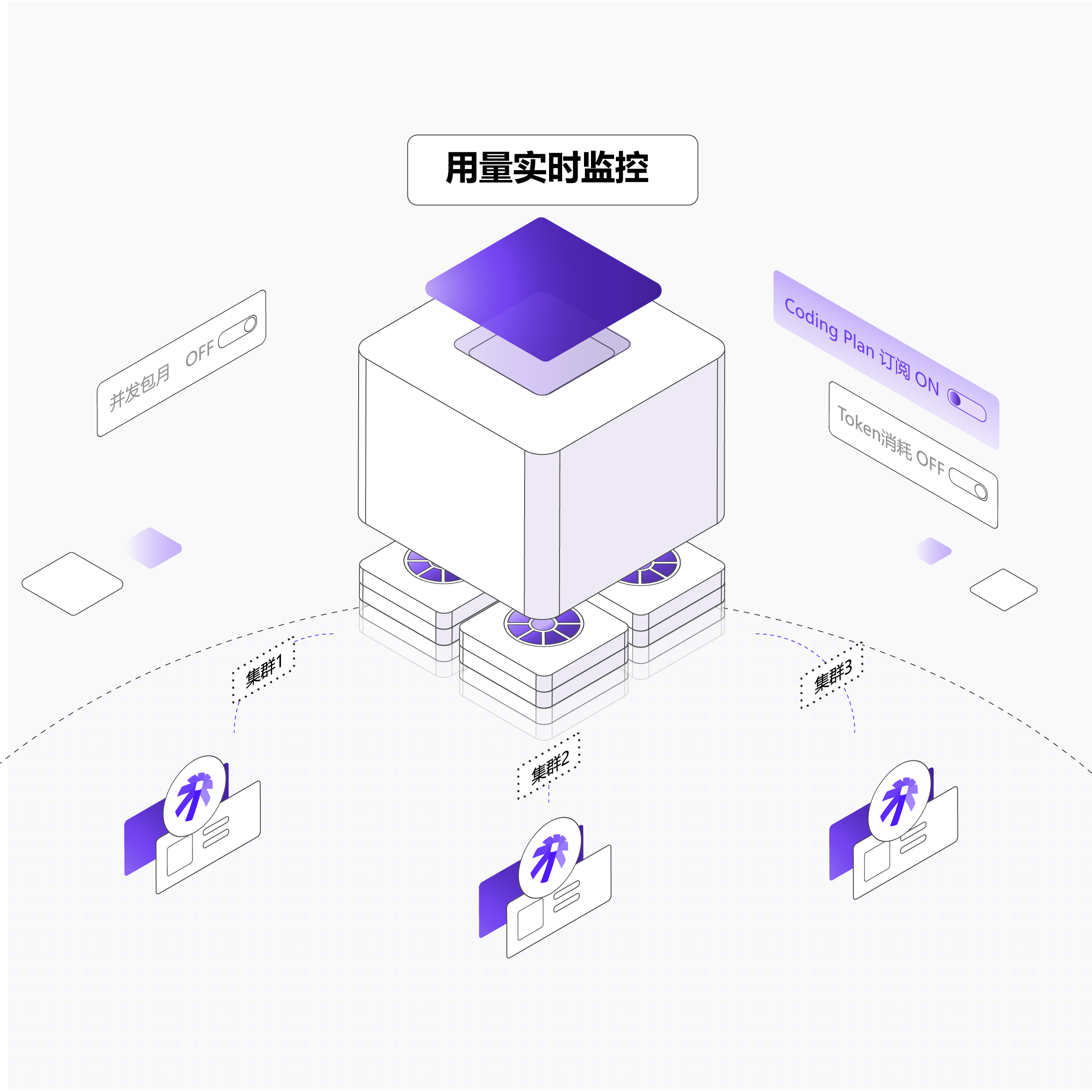
提供多样化的计费模式与订阅方案,满足不同规模、不同场景的客户需求,让成本可控、使用灵活。
多样计费模式:支持按token计费,按并发包月,Coding Plan订阅等多种不同的计费方式,满足不同流量的特征的业务与客户的需求
用量实时监控:用量精确到单模型、单Token计量,成本透明,剩余额度、使用趋势实时可见
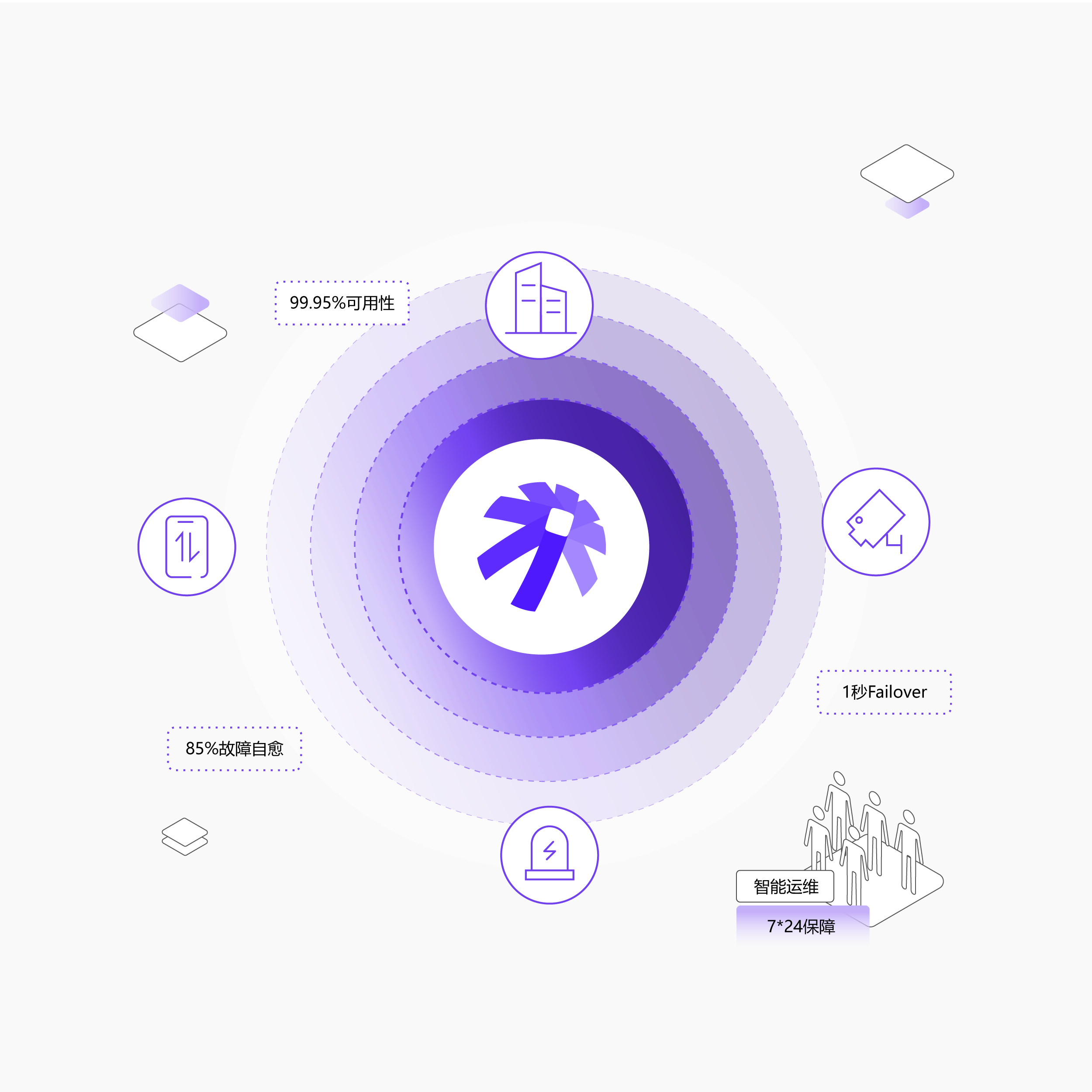
基于Agent技术打造的自愈式、自优化的智能运维体系,保障模型服务7×24小时稳定运行
全方位健康检查:对服务、实例、请求、业务等多个维度进行全方位分析检查
异常自动识别:自动分析日志、监控数据、请求链路,快速定位问题根源
智能容量管理:根据历史业务特性,提前预警业务高峰,合理维持容量水位生成扩缩容建议
人机协同变更:故障实例自动摘除,服务升级变更方案人机协作决策,记录可追溯审计
提供从模型接入、流量治理、推理优化到资源调度的全栈系统能力
以Agent赋能极致工程优化的大模型推理服务系统,让AI能力真正产品化
为什么选择无问芯穹
客户故事
某头部大模型独角兽
为数百万用户提供AI服务,覆盖C端网页应用、移动APP、以及面向B端企业的API接口。日均推理请求量千万级,7×24小时不间断运行,需兼顾模型精度、响应速度与服务稳定性。
发布依赖多部门:每次模型更新需预估流量、协调资源,需持续投入优化推理体验,无法聚焦模型效果迭代
量化加速牺牲精度:普通供应商量化后精度损失难以及时发现,导致工具调用准确率下降,用户口碑受损,B端投诉上升
平稳承接数万QPS突发流量:营销活动期间零中断,用户留存率提升15%,问题定位从小时级压缩至分钟级
团队效能释放:业务规模增长一个数量级,资源可聚焦于模型效果迭代
精度可量化、可评价:建立标准化的模型服务精度评价体系,为模型能力树立扎实口碑

扩容速度跟不上流量:突发热点导致请求量激增百倍,实例扩容慢,线上服务失败率飙升,用户体验差
任务混杂调度乱:同步/异步模型混跑,优先级不清晰,无法针对性做推理优化,生图耗时过长,用户易跳出
版本管理复杂:模型与环境多个版本管理复杂,业务需要高频更新,版本控制与流量调度难以协同
分钟级快速扩容:新增热点流量全量接入平台,1分钟内完成扩容,减少上百万请求的用户流失
推理性能大幅提升:推理任务速度提升80%以上,对话文本吞吐提升1倍以上,用户流失率降低71%
迭代效率质变:按业务属性灵活接入不同模型API,无需自研队列分发策略,迭代周期从周级压缩至日级
释放无穹智能,让AGI触手可及
联系我们,获取定制化 AI 基础设施解决方案

