

核心痛点
-

推理体验作为用户增长与留存的核心指标,
性能波动影响用户增长多模态应用推理链路长,高并发下时延抖动与服务不稳定频发,影响终端用户体验与商业转化效率
-

算力成本高叠加业务需求波动,
成本效益优化成为企业发展关键算力投入重、部署周期长,业务流量峰谷显著,易造成资源闲置与成本浪费,制约商业化初期企业生存与发展
-

模型迭代周期短,且训练工程复杂、环境与
版本不一致等导致工程化成本高模型快速迭代成常态,但训练环境复现、版本管理、分布式调优等环节复杂,导致模型从训练到上线的工程化成本高昂,影响核心竞争力
-

企业商业化进程对模型训练及推理的稳定性
提出极高要求长周期训练对硬件故障、网络/存储抖动敏感,容错性要求高;推理侧同样需应对高并发与节点异常。缺乏系统容错与高可用机制将影响业务可用性
-

基础设施运维繁重,
挤压核心创新投入企业大量人力投入集群运维、故障排查与资源调度,分散研发精力,难以聚焦模型创新与产品打磨
全栈AI基础设施,加速多模态模型规模化商业落地
无问芯穹AI原生企业解决方案,面向多模态模型企业,针对模型研发与商业化运营中的训练效率、推理体验、系统稳定、成本可控、运维高效等维度,通过智能资源管理与调度、平台级研发环境支撑、训练加速与稳定性保障、推理优化与多模态业务编排、精细化资源运营、全托管运维与高可用保障六大能力模块的深度协同,构建系统性能力闭环与可对外承诺的交付运营体系,帮助企业以健康的成本结构加速商业化落地,构筑可持续的生态壁垒。

核心优势
更快更稳的推理,更迅速的迭代,更省的业务成本

推理性能显著提升,提升用户留存

自研推理引擎结合量化、KV-Cache优化等系统级加速,推理加速最高达50%,降低用户等待时延
适配多模态应用长链路形态,支持复杂业务编排与异步并发,保障全链路响应一致性与高并发稳定性
内置健康检查与自动恢复机制,有效规避单点故障,确保线上服务与用户体验的连续性
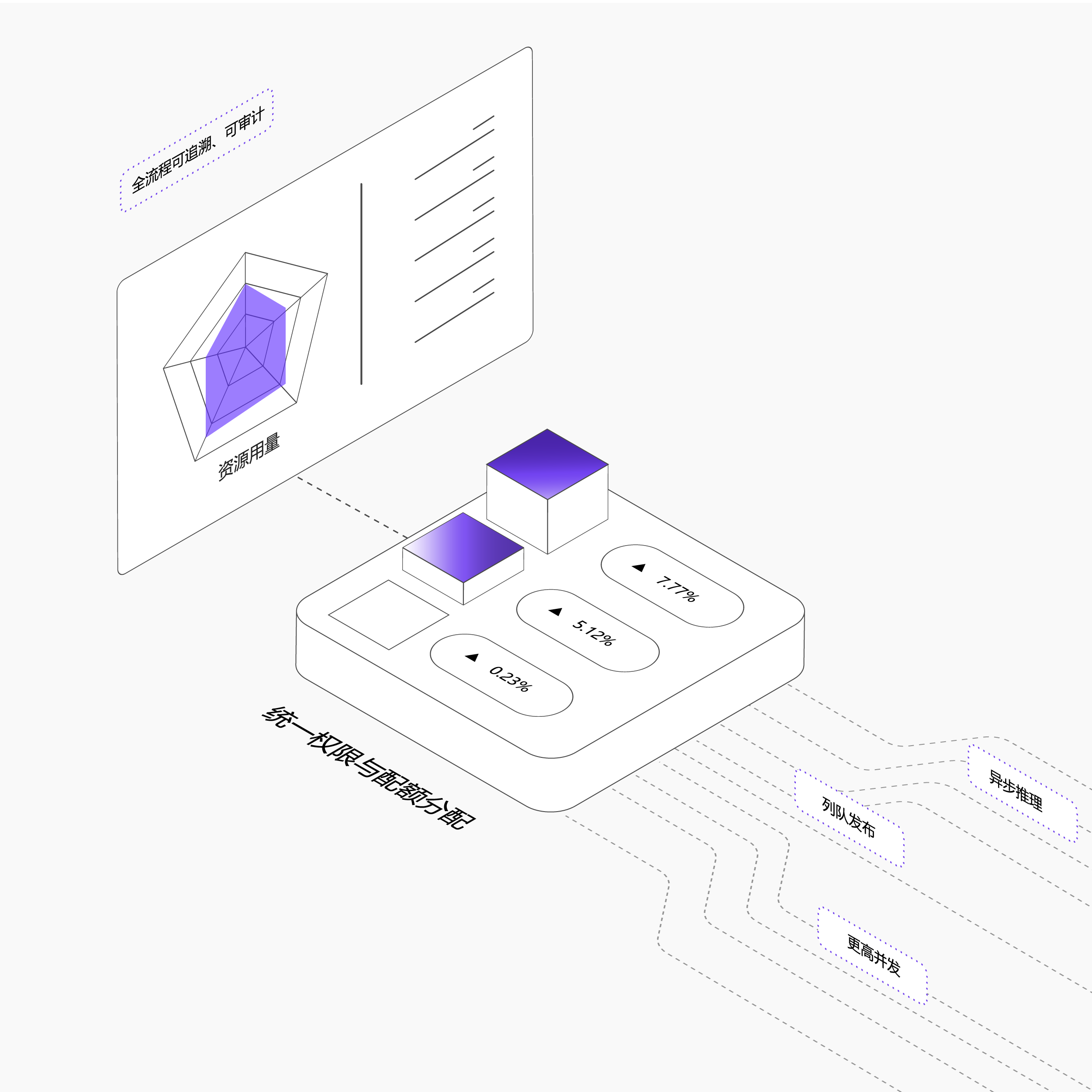
成本结构更可控
根据不同任务特征自动适配算力配置,结合业务流量峰谷弹性扩缩容,反碎片调度减少算力空洞
统一权限与配额分配,多团队采用独享+共享双资源池策略降低初期算力投入成本
基于容器化架构,实现异步推理、队列分发,同等算力更高并发,提升资源利用率与服务稳定性
资源用量全流程可追溯、可审计,支撑精细化成本核算与预算管控
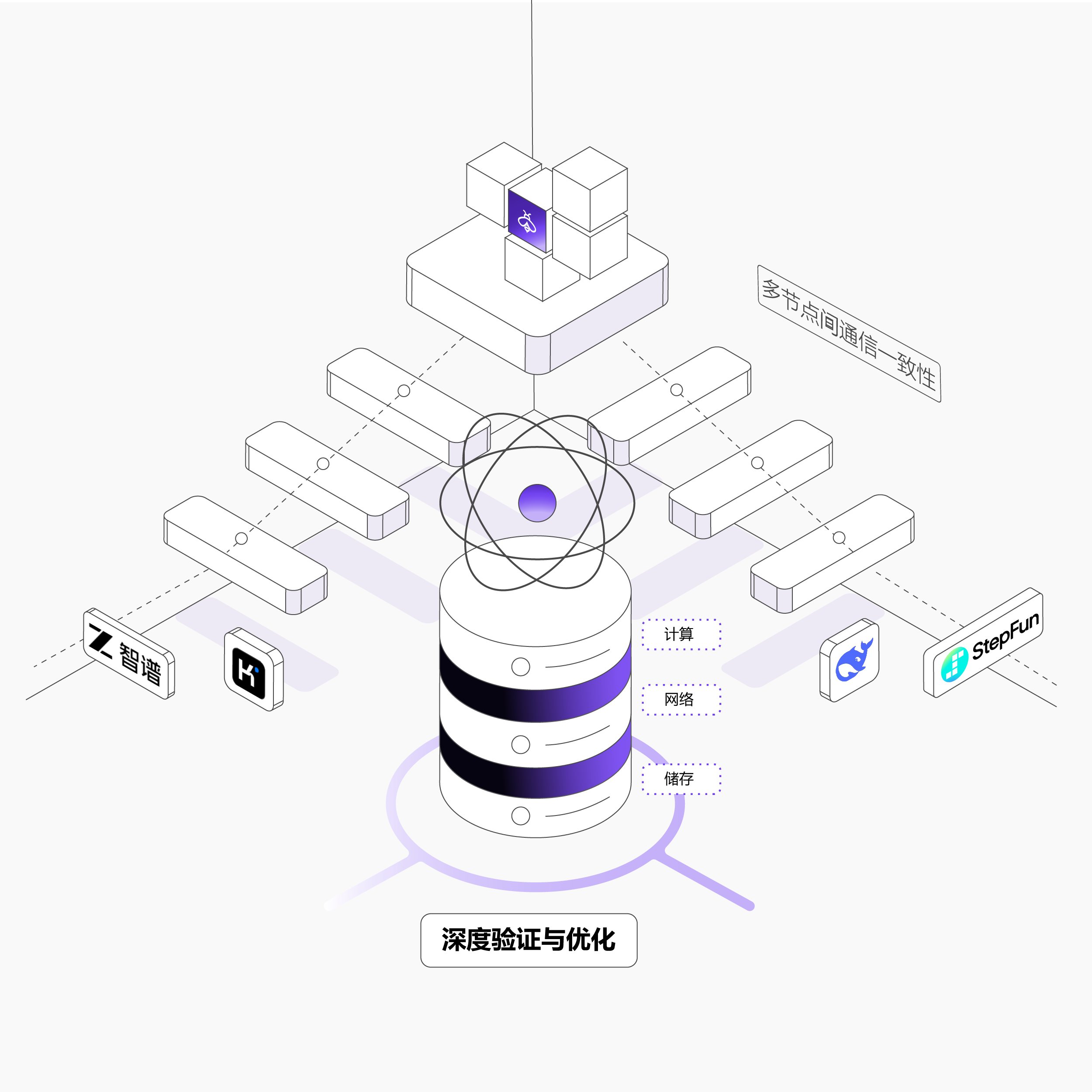
全链条稳定性保障
计算、网络、存储等核心组件经过深度验证与优化,降低长周期训练中的硬件故障率
建立关键链路冗余热备与故障快速切换机制,单点故障不影响整体任务运行
网络通信预优化保障多节点间通信性能一致,大规模训练任务可快速拉起
自动实时检测硬件异常与通信故障,热迁移无缝切换,异步checkpoint确保训练进度不丢失
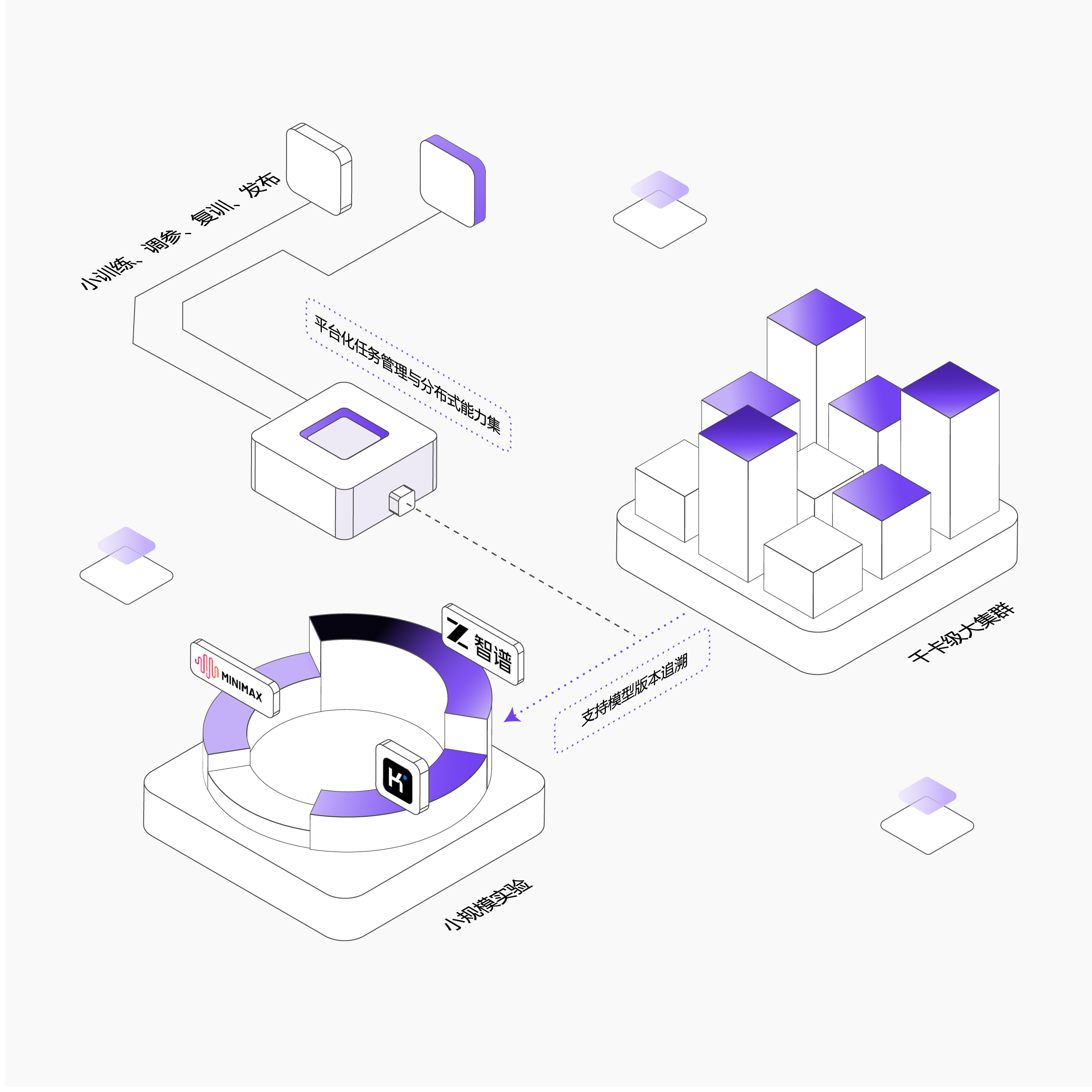
迭代与上线更高效
预置主流机器学习框架镜像,提升开发、测试环境一致性,消除跨环境复现难题
平台化任务管理与分布式能力集成,训练、调参、复训、发布等环节自动串联,大幅提升迭代效率
支持模型版本追溯与实验效果对比,快速定位最优配置,缩短调优决策路径
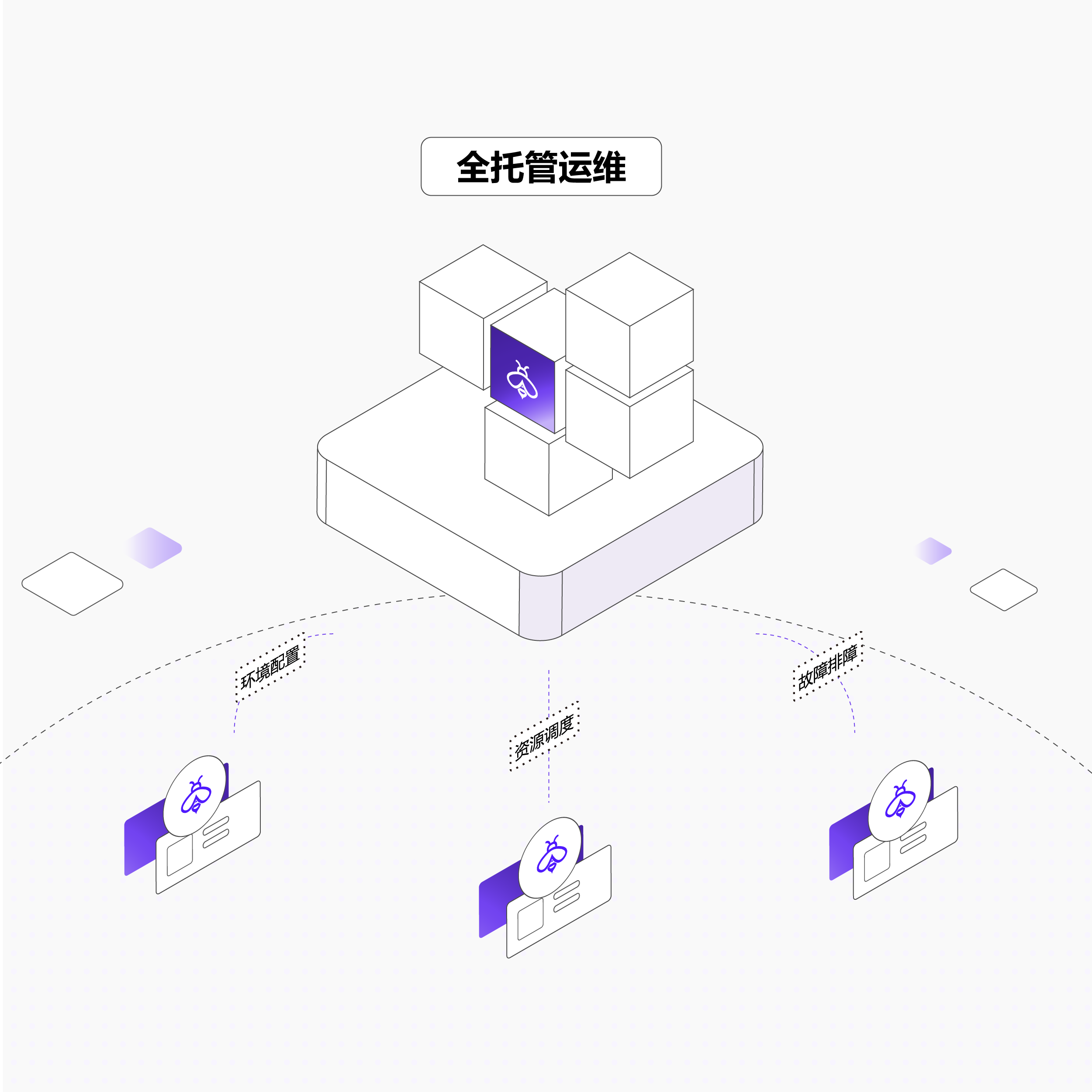
运维显著减负
提供从集群部署、系统配置到日常巡检的全生命周期软件运维能力,客户无需自建基础设施运维团队
全天候监控与快速响应机制,确保业务持续稳定
环境配置、资源调度、故障排查等由平台工具自动化承接,释放团队资源聚焦产品创新
行业价值
-

加速商业化落地
从模型就绪到服务上线全链路自动化,平台级开箱即用环境、任务管理流水线与推理引擎优化协同,模型上线周期最高缩短30%,帮助企业以时间优势抢占市场先机、加速数据飞轮
-

构建健康成本结构
弹性调度、双资源池、反碎片调度与智能匹配多维并举,GPU利用率最高提升25%,综合业务成本最高下降55%,让算力从粗放消耗转向精细化运营,为可持续盈利奠基
-

保障业务连续性
全链条冗余热备、分钟级故障恢复与7x24小时监控响应,服务可用性超99.5%,有效训练时长最高提升30%,稳定支撑规模化商业交付
-

释放创新动能
全托管运维将基础设施从人力密集型转为平台能力型,让企业人才回归模型创新与产品迭代
-

支撑规模化生态构建
从小规模实验到千卡级大集群的弹性扩展能力,帮助客户从“单一模型提供者”进化为“平台型AI服务商”,支撑更大规模的用户接入、更丰富的应用场景和更完善的开发者生态
行业案例

无问芯穹&生数科技,分钟级弹性架构护航Vidu视频模型高并发与资源优化
针对生数科技Vidu视频大模型多子模型复杂业务流程及推理流量峰谷显著的挑战,无问芯穹提供基于K8S的弹性算力平台,实现分钟级动态扩缩容与训练推理资源统一管理。高峰时自动扩容承接激增流量,低谷时即时缩容释放闲置资源,综合生产成本大幅降低;同时保障训练连续三个月以上稳定运行,有效使用时长超97%,为模型快速迭代与业务爆发式增长提供坚实可靠的基础设施支撑。

无问芯穹&VAST,训推与高速存储统一平台打通3D大模型训练全流程
针对VAST 3D大模型Tripo训练中数据传输慢、存储压力大、算力割裂等瓶颈,无问芯穹提供高速分布式存储与统一训练推理平台,将数小时的数据传输压缩至分钟级,数据处理、模型训练与推理验证在同一平台无缝衔接。工作流从割裂低效整合为一体化流水线,模型迭代速度显著提升,助力Tripo实现8秒生成带纹理3D网格模型的全球领先性能,持续巩固3D AIGC领域头部地位。
释放无穹智能,让AGI触手可及
联系我们,获取定制化 AI 基础设施解决方案

