


多元异构算力优化 极致提升资源利用效率
支持NVIDIA、AMD、华为昇腾等10+主流AI芯片的池化管理与智能调度
丰富的硬件生态
智能池化与调度
全链路实时可观测
自动化运维愈障
10+
支持10+主流芯片
85%+
资源利用提升
50+
核心指标监控
85%
故障智能自愈
核心能力
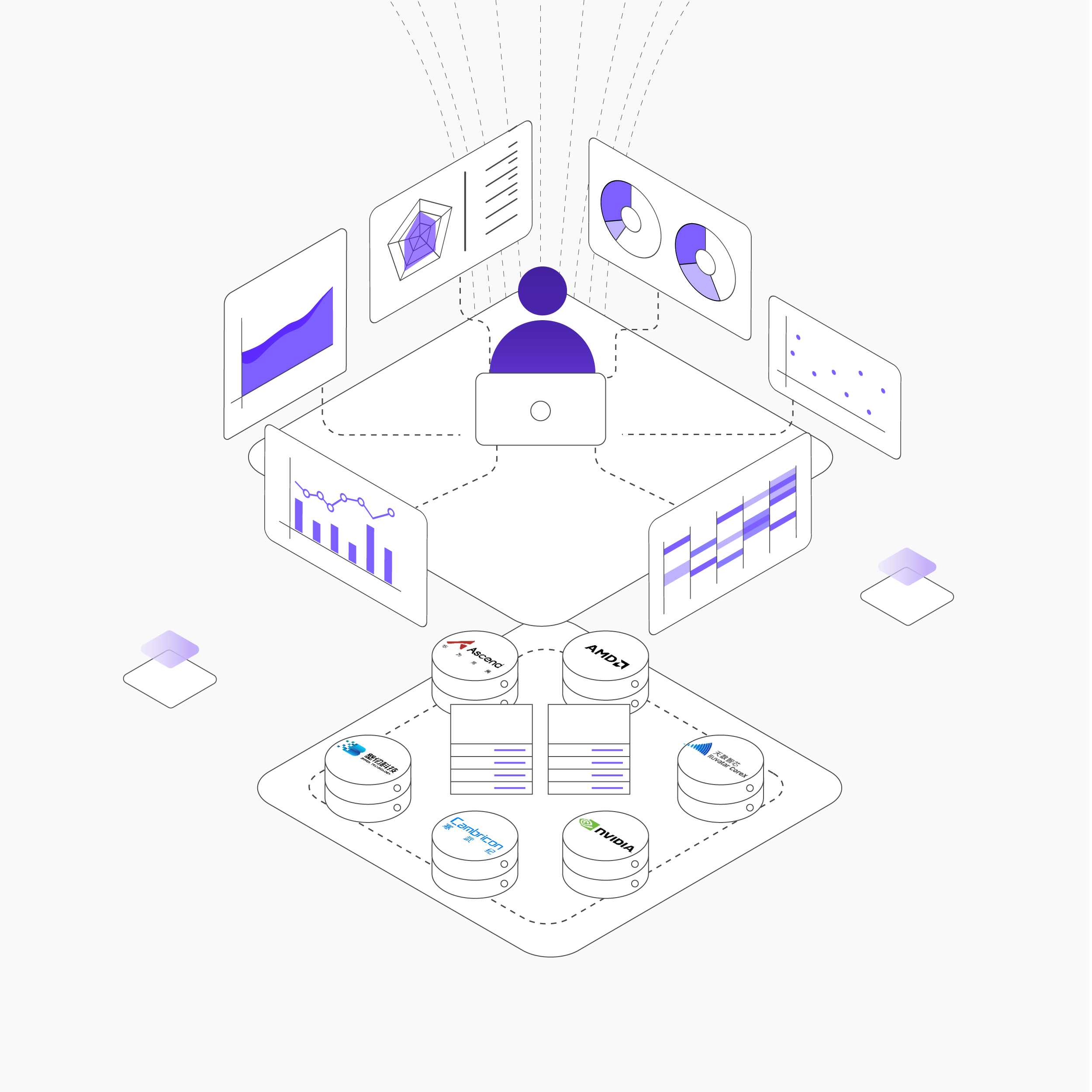
全面芯片生态: NVIDIA、AMD、华为昇腾、天数、沐曦、壁仞等多种芯片主流系列全面支持。
屏蔽硬件差异: 统一的资源描述模型,上层应用无需关心底层芯片类型
统一接口兼容: 提供统一的资源申请、监控、管理接口,计算能力、内存容量、互联带宽等统一量化

自动资源池化: 支持按多种芯片类型、地域与场景等维度进行自动池化
动态资源调配: 资源池间动态调整,应对负载变化,支持碎片资源自动整合,降低资源碎片化
多策略调度算法: 支持拓扑感知、Bin-packing、Gang调度、优先级调整、抢占式调度等多种智能调度策略

多维度数据采集: 支持包括硬件层指标、任务层指标、集群层指标、统一监控等多种维度的全面数据采集
多级智能告警: 根据不同情况实现告警分级、告警聚合与抑制,降低80%以上无效告警,并支持多渠道的实时通知闭环
跨平台协同处理: 支持基于集群与运维平台的告警,与训推服务平台的感知联动,高效打通从资源下层到上层的信息壁垒
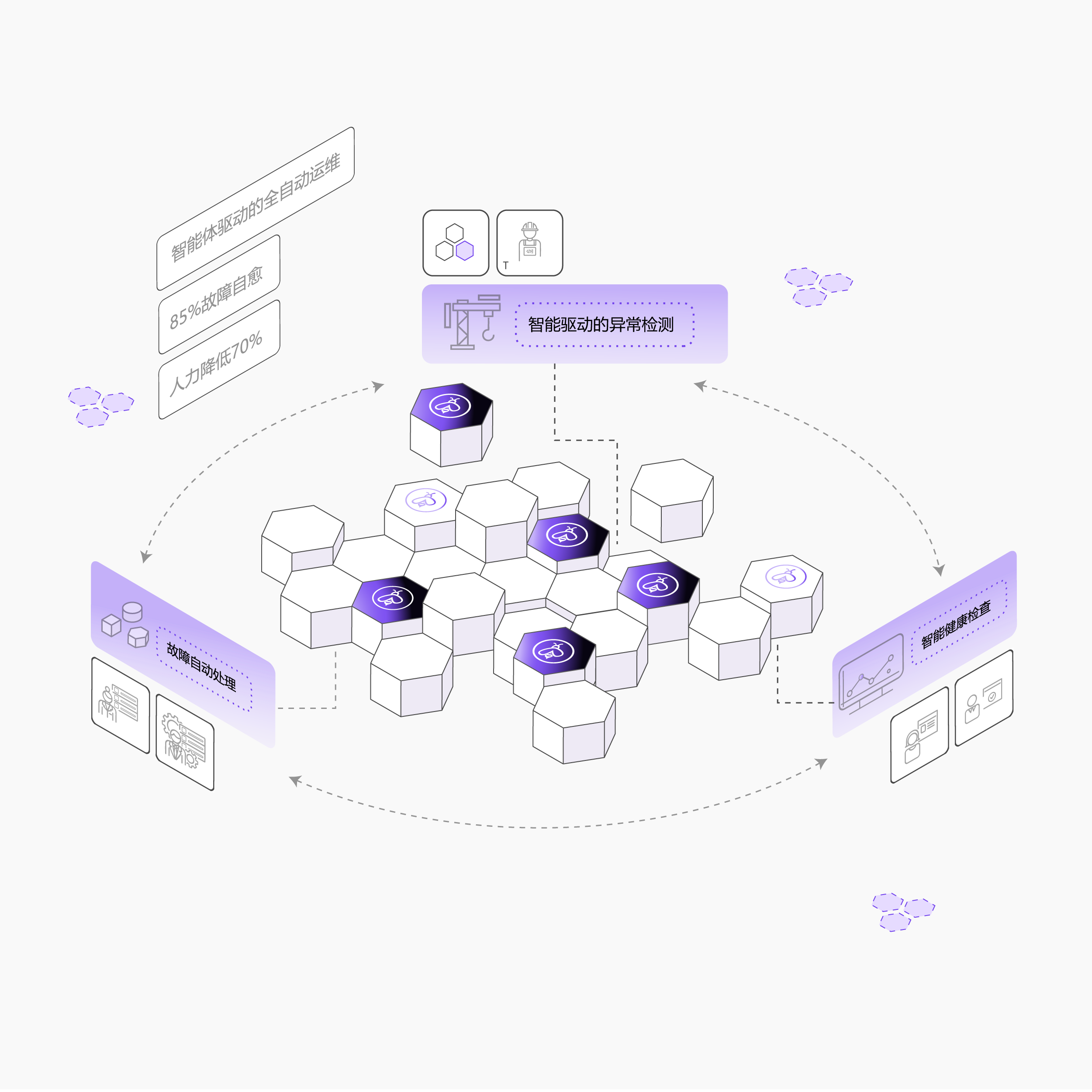
智能驱动的异常检测: 支持包括性能异常、温度异常、慢节点等多种异常情况的预测与识别,自动分析异常情况
智能健康检查: 对机器硬件、网络、存储等多种维度的健康监测,并定期自动执行健康检查拨测任务
故障自动处理: 对检测到的故障节点实现自动隔离,并实现相应负载的迁移,支持自动重启与配置回滚
为什么选择无问芯穹
客户故事

芯片纳管割裂:多套平台割裂,进口与国产芯片无法统一纳管
迁移成本高昂:业务迁移成本高,需为每种芯片重复适配
故障定位复杂:故障定位需多方协调,处理链路复杂,排障效率低下
自行对接低效:自行对接开发周期长,影响研究进度,功能被迫阉割
落地进度缓慢:资源调度差,国产芯片落地缓慢,业务部门矛盾突出
统一纳管:一套软件纳管所有芯片,实现统一监控与池化管理
多租户隔离:多业务部门按预算配额隔离,操作互不干扰
迁移成本降低:平台预适配大幅降低迁移成本,业务仅需少量开发
高效运维:全链路可观测快速定位故障,运维效率倍增
智能调度:智能调度策略实现灵活借调,利用率提升,等待时间减少
预算分配难:多业务单位预算无法在多种芯片上等比例分配,资源类型争议不断
迁移依赖重:业务指定芯片型号,迁移需厂商双边配合,适配成本高昂
接入周期长:新算力供应商对接复杂,纳管需数月,资源长期供不应求
灵活配额:多业务部门按预算实现多租户资源隔离,支持实时交易结账
按需调度:业务按需指定芯片类型,池化调度系统自动拉起负载,无需额外适配
极速接入:新机器由基座自动标准化接入,供应效率与体验大幅提升
释放无穹智能,让AGI触手可及
联系我们,获取定制化 AI 基础设施解决方案

