
2025年1月20日,集成电路设计自动化领域的国际传统顶级会议之一的ASP-DAC(Asia and South Pacific Design Automation Conference, 亚洲及南太平洋设计自动化会议)在日本东京召开。在ASP-DAC成立30周年之际,今年的前端最佳论文奖颁发给了《ViDA: Video Diffusion Transformer Acceleration with Differential Approximation and Adaptive Dataflow》——由无问芯穹与上海交通大学联合研究团队提出的视频生成软硬一体加速器,首次实现通过差分近似和自适应数据流解决VDiT生成速度缓慢瓶颈,推理速度相比A100提升高达16.44倍。

论文第一作者丁立和共同第一作者刘军均来自上海交通大学,通讯作者戴国浩是上海交通大学副教授、无问芯穹联合创始人兼首席科学家。据悉,这是该团队继2019年以结构化稀疏与软硬件联合设计打破加速记录之后,再次以差分稀疏化和软硬协同方案创造加速记录,第二次斩获ASP-DAC最佳论文奖。

据Fortune Business Insights数据,2024年全球AI视频生成市场规模达6.148亿美元,预计到2032年将飙升至25.629亿美元。当下,视频生成模型的视频长度、细节逼真度和运镜流畅度都在快速提升,在可以预见的未来,绝大多数视频任务将由AI视频生成模型辅助完成。然而这些模型需处理高维度时空数据,计算复杂度极高,尤其在高分辨率、长时序场景下,对计算资源的消耗巨大,给内容创作、虚拟现实等产业带来严峻挑战。
即便是资金雄厚、设备高端的工业级影视制作团队,也难以承受当下AI视频生成模型带来的高昂时间成本、计算成本和算力浪费。在此背景下,视频生成模型推理加速等基础研究工作将有望为产业带来百亿级市场的深远影响。
如何有效地加速视频生成模型的推理过程,不仅对模型性能的优化提出了更高的要求,也成为推动生成技术落地的重要瓶颈问题。这一背景下,针对特定生成任务设计高效的计算架构和优化算法成为当前的研究重点。以OpenAI的Sora为代表,视频扩散Transformer(VDiT)模型的最新进展极大地推动了视频生成领域的发展。然而,VDiT推理过程中仍然存在帧间计算冗余和算子计算强度差异较大的问题。现有基于有限帧间相似性的计算方法以及静态硬件架构和数据流设计,无法有效解决VDiT推理速度缓慢的瓶颈。为应对上述挑战,作者团队结合帧间预测的差分计算与帧内稀疏特性的分析,提出了视频生成模型的软硬一体加速器ViDA,创造性地通过差分近似方法和自适应数据流架构,利用稀疏性实现软硬件协同优化,从而大幅提升了VDiT的推理性能。在多种主流VDiT模型上的实验结果表明,与NVIDIA A100 GPU和现有最先进加速器相比,ViDA分别实现了平均16.44倍/2.18倍的加速比和18.39倍/2.35倍的面积效率提升。
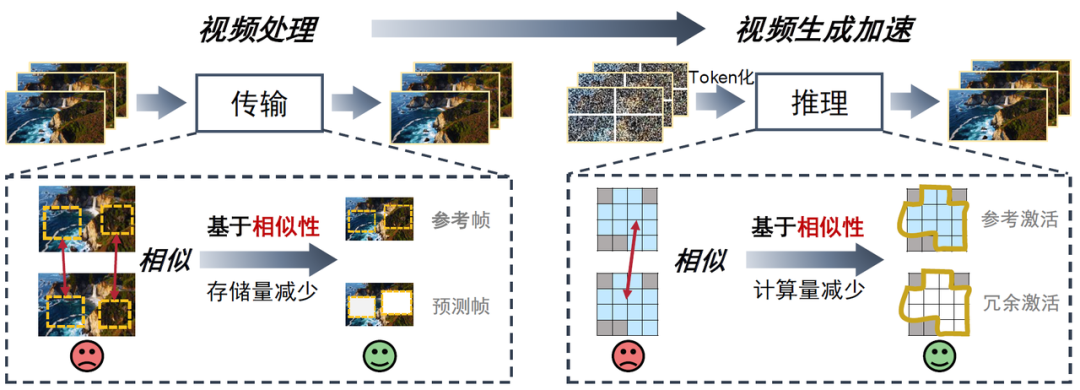
图 1:从视频处理到视频生成加速
ViDA的设计深受传统视频处理中基于相似性去除帧间冗余方法的启发。如图1所示,在传统视频处理中,帧间的高相似性被充分利用,通过对相邻帧进行分块比较,将当前帧的内容表示为参考帧的基础上叠加变化信息,从而有效去除帧间的冗余。这种方法不仅减少了存储和传输中重复数据的占用,还能通过优化预测和补偿机制,大幅提高视频编码的效率。这种基于相似性的优化策略为传统视频处理提供了显著的存储与传输优势,同时也为生成模型的推理优化提供了重要参考。
基于这一理念,ViDA结合视频相似性预测的差分计算,提出了一套面向视频生成模型的优化方法。通过深度挖掘生成过程中的帧间激活相似性,ViDA有效减少了计算冗余,为推理效率和硬件性能的全面提升奠定了基础。
1. 首先,在算法层面,本文提出了差分近似计算方法,成功减少了Act-Act算子51.67%的计算量;
2. 其次,在硬件层面,设计了列聚集处理单元,利用差分计算中的列稀疏模式,使面积效率提升了1.47倍;
3. 最后,在数据流层面,构建了计算强度自适应数据流架构,将计算效率提升了1.76倍。
在视频生成领域(包括图像生成),大量研究已经证实了视频扩散变换器(VDiT)的显著扩展潜力,例如Sora模型。通过“Patchify”方法,VDiT将视频中不同帧转换为统一的时空序列(即patch),从而获得类似于大规模语言模型(LLMs)中tokens的统一数据表示。尽管当前的视频生成质量取得了巨大进步,但生成速度仍然较慢。我们发现阻碍VDiT加速的两个主要挑战如下:
挑战一:VDiT推理仍存在大量帧间冗余计算。
VDiT采用多帧并行推理的方法生成视频,但由于帧间相似性,多帧激活计算中存在冗余。如图2所示,现有研究包括ViTCoD [HPCA 2023], InterArch [DAC2024]和CMC [ASPLOS 2024]主要利用帧内相似性,但帧间相似性仍未被充分利用。现有工作仅考虑对Act-W算子(如QKV投影和O投影)进行差分计算。然而,由于激活-激活(Act-Act)算子的非线性表达,VDiT中的Act-Act算子(如Logit和Attend)无法使用这些差分计算方法,VDiT中仍有56.97%的计算无法通过现有差分计算方法加速。
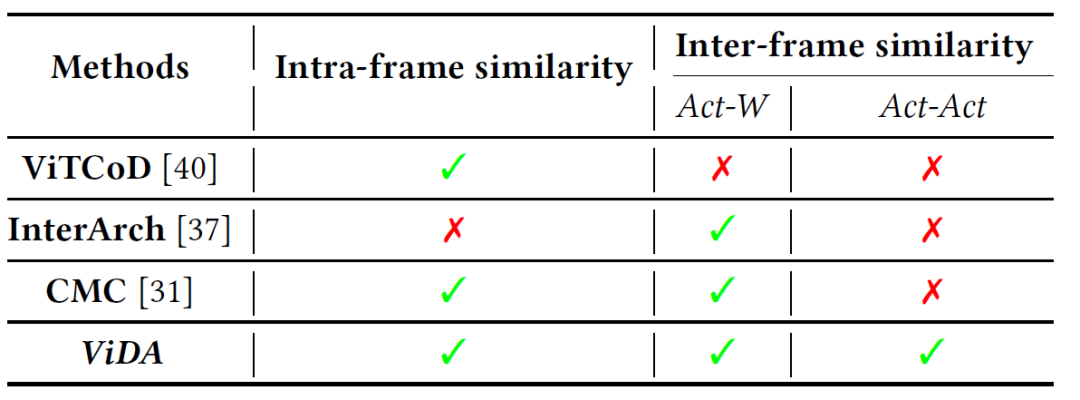
图 2:从相似性的角度与现有方法的比较
挑战二:VDiT算子的计算强度差异较大,导致利用率低下
在文本生成中,大型语言模型(LLM)推理的主要耗时过程是生成单一token的向量。由于KV缓存的存在,LLM推理中的算子表现出较低的计算强度,不同算子之间的差异也较小。在图像分类中,视觉Transformer(ViT)同时对所有tokens进行计算。由于图像大小相近,ViT中不同算子的计算强度差异也较小。然而,在视频生成中,随着帧数增加,Act-W操作与Act-Act操作的计算强度差异超过10倍。VDiT在时间维度上的计算和内存资源需求不断变化,因此现有为文本和视觉任务设计的静态架构和数据流无法充分应对这一问题,导致硬件利用率小于40%。
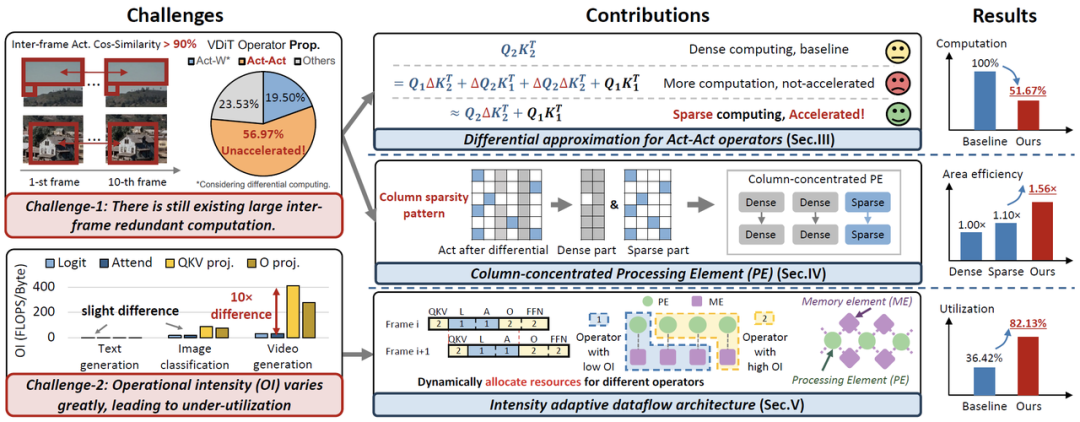
图3:ViDA(一种基于差分近似和自适应数据流的VDiT加速器) 概述,探索了差分近似方法和自适应数据流架构
针对挑战1,我们提出了差分近似方法,可在Act-W和Act-Act算子中消除冗余计算。通过利用帧间相似性,这种方法将Act-Act操作的冗余计算减少了51.67%。
基于差分近似方法,我们进一步提出了列聚集处理单元,以利用列稀疏模式。相比仅支持稠密或稀疏的PE,该方法在面积效率上分别提高了1.56倍和1.42倍。
针对挑战2,我们提出了一种计算强度自适应数据流架构,可动态分配资源以适配不同算子的执行需求。通过设计路由控制器平衡操作的执行,性能相比静态数据流架构提高了1.76倍。
我们在多个VDiT模型上验证了ViDA的加速性能。与NVIDIA A100 GPU和SOTA视觉加速器相比,ViDA分别实现了平均16.44倍/2.18倍的加速比和18.39倍/2.35倍的面积效率提升。
视频扩散Transformer(VDiT)
通过将视觉变换器(ViT)引入扩散模型,VDiT在Sora等视频生成工作中取得了前沿性能。生成视频的主要耗时阶段是通过VDiT在多时间步中预测需要去除的噪声,因此加速VDiT的计算至关重要。
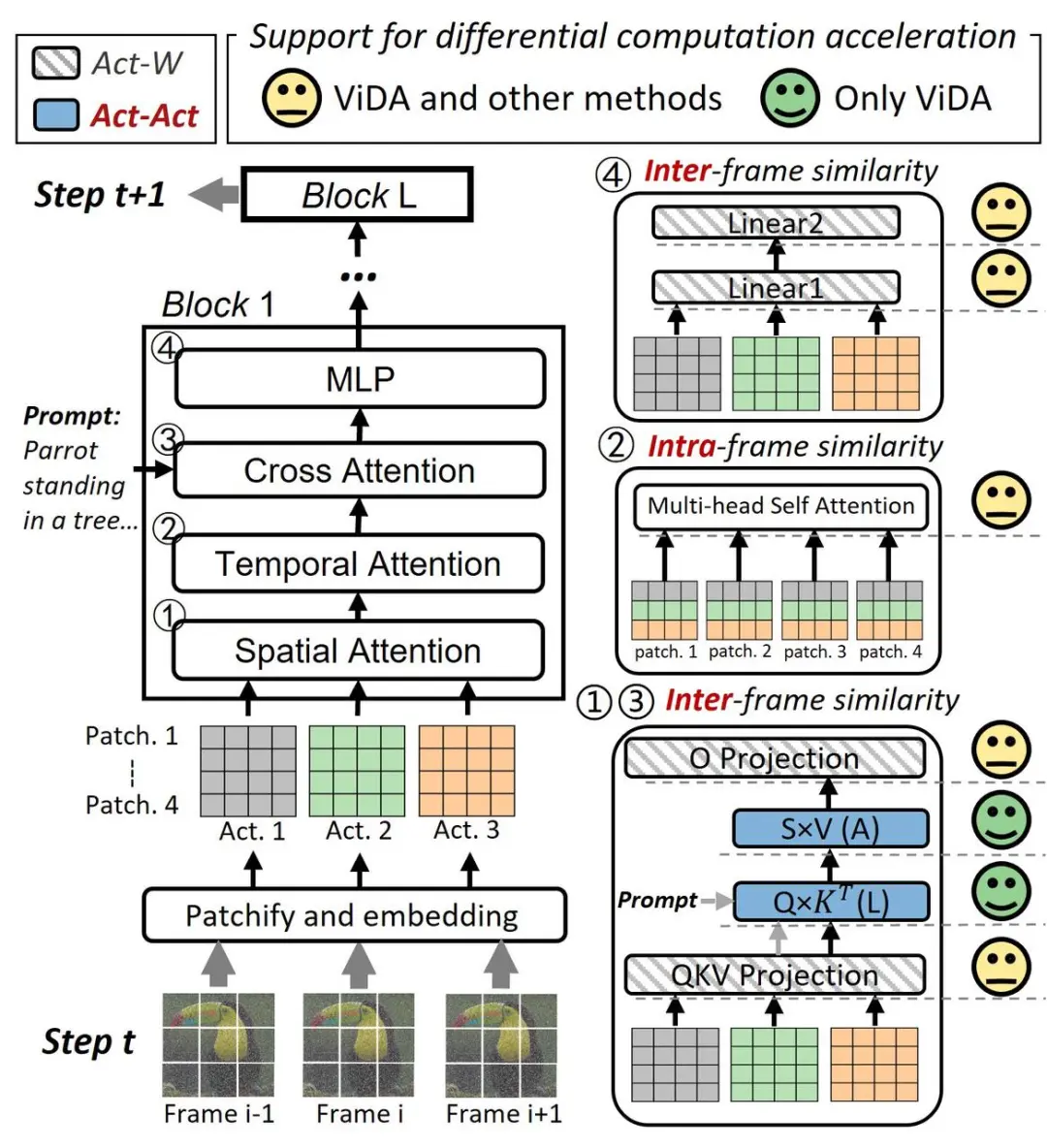
图 4:VDiT模型架构图
图4展示了VDiT的基本架构图。在某个去噪时间步t,经过分块及位置嵌入后,噪声帧被转换为激活数据,作为Transformer块的输入。每个块由四部分组成:空间注意力(S-A)、时间注意力(T-A)、交叉注意力(C-A)和多层感知器(MLP)。模型通过S-A和T-A学习视频的空间和时间信息,通过C-A学习文本或图像条件信息。经过L层变换器块后,模型预测噪声并去噪图像,并进入下一时间步t+1。
差分计算
差分计算通过利用激活值之间的相似性来减少计算量。具体来说,下一帧F+1的激活值XF+1可以表示为当前帧F的激活值XF加上一个增量部分ΔX。由于当前帧和下一帧之间的激活值通常具有很高的相似性,因此ΔX中的许多元素非常接近于零。可以设置一个对模型精度影响可接受的阈值,将小于该阈值的增量部分元素视为零。
通过这种方法,可以实现数据的稀疏化,因为在数学计算中,零值与任何值相乘的结果仍然是零,从而有效减少计算量。尽管差分计算在传统深度学习中已取得成功,例如Cambricon-D [ISCA 2024]在ReLU激活函数中引入了这一技术,但在VDiT模型中,主要的注意力机制包含了大量激活-激活(Act-Act)算子。这些算子具有非线性特性,现有的差分计算方法无法直接适用,因此在VDiT中的加速效果较为有限。
06 技术要点
差分近似方法
现有工作中考虑帧间相似性的方法未能对Act-Act算子进行加速,主要原因在于差分计算无法处理其非线性特性。然而,Act-Act计算在VDiT中占据了显著比例。
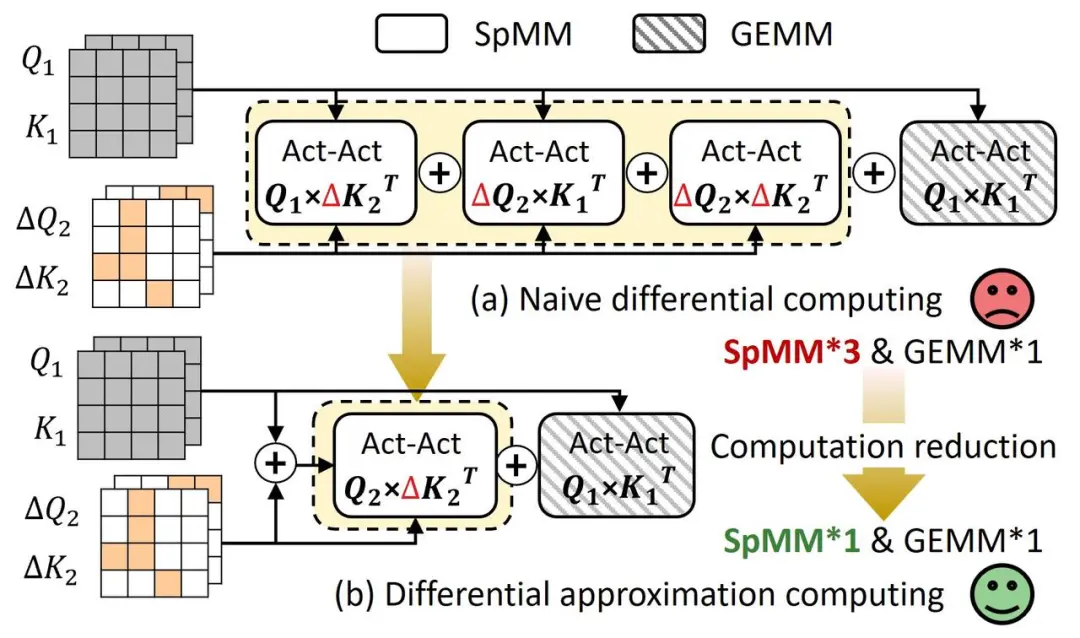
图 5:Act-Act 算子的(a)无优化的差分计算与(b)差分近似计算的比较
如图5(a)所示,我们选取一个特定的激活作为参考激活,对冗余激活执行差分剪枝操作后,冗余激活的Act-Act计算可以拆解为4个部分,需要进行三次稀疏矩阵-矩阵乘法(SpMM)计算,不能实现计算效率提升。
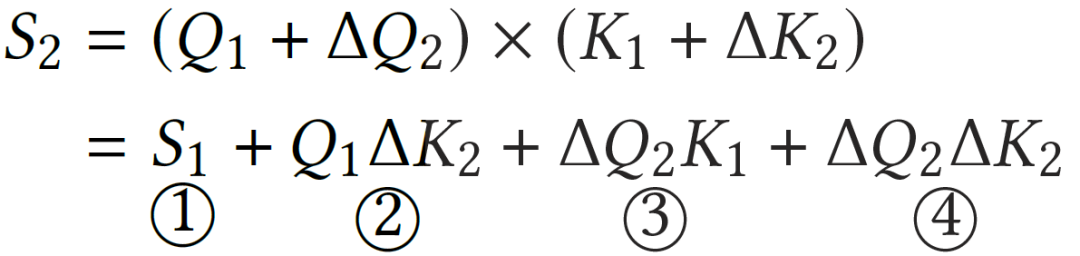
为了简化计算,如图5(b),我们对多种Act-Act操作的值进行了数值分析。结果表明,第二项和第三项的数值比第一项小两个数量级以上,并且没有显著的异常值。因此,可以忽略第二项或第三项以简化计算,从而减少SpMM数量。
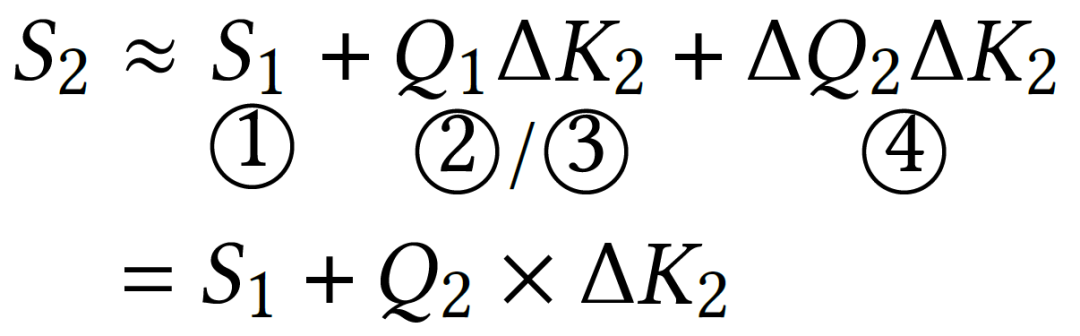
此外,我们的近似计算在余弦相似度上的一致性平均超过98%,对Act-Act操作的精度影响可以忽略。通过此方法,与稠密计算相比,Act-Act操作的计算开销减少了51.67%。
列聚集处理单元
我们观察到这些激活呈现出列稀疏性模式,这是因为patch向量之间的编码格式具有一致性。实验发现,激活矩阵中87.94%的非零值聚集在不到23.50%的列中。利用这一稀疏性模式,可以将稀疏列和稠密列进行细粒度拆分计算,从而实现面积效率的提升。如图6所示,为了利用稠密硬件低面积消耗和稀疏硬件低计算开销的优势,我们提出了列聚集处理单元(PE),其硬件设计包括分配单元、合并单元、稠密计算阵列和稀疏计算阵列。
如图6(c)所示,稠密计算使用普通脉动阵列格式,稀疏计算则通过队列形式输入非零值,从而在稠密与稀疏计算之间实现硬件利用率的平衡。如图6(d)所示,对于CSC格式的稀疏激活,分配单元根据非零值比例动态分配列到稠密或稀疏数组执行计算,优化任务分配并提高硬件利用率。
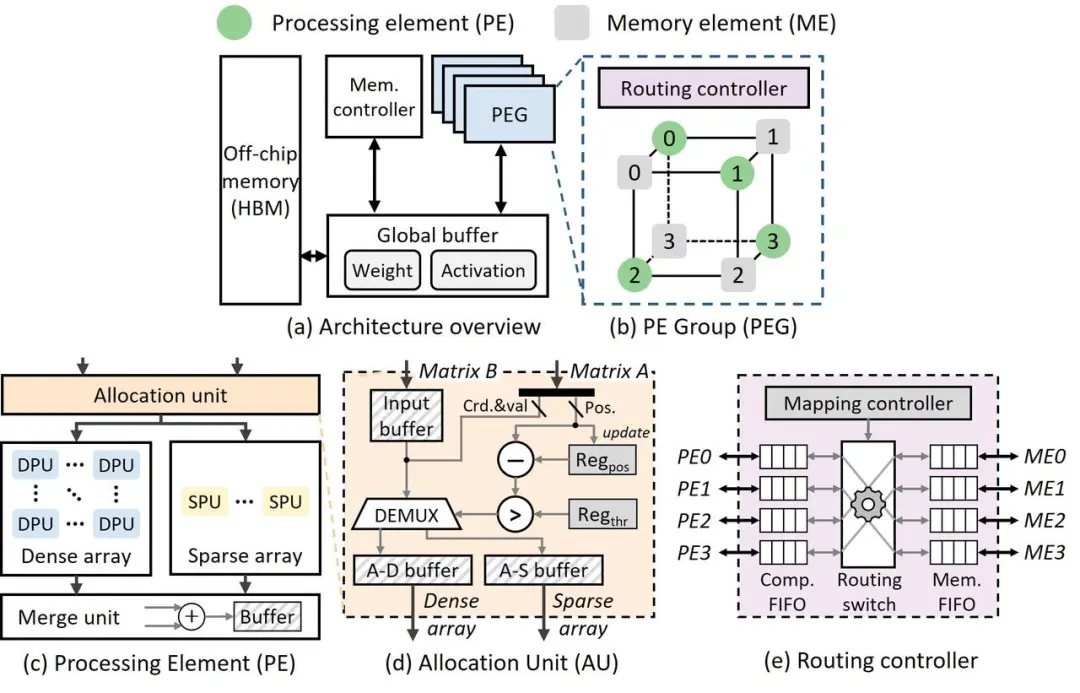
图 6:硬件架构概要
计算强度自适应数据流架构
VDiT的算子计算强度差异明显,特别是Act-W与Act-Act操作之间。我们提出了一种可重配置计算架构,通过动态分配计算和存储资源,实现硬件利用率最大化。
计算强度自适应数据流:
1. 资源平衡:针对注意力计算中计算强度差异大(如图7(a)),对Logit和Attend操作优化内存访问压力,对QKV和O投影操作优化计算密集度,提升处理单元(PE)和内存带宽的利用率。
2. 跨帧优化:利用不同帧计算的独立性(如空间注意力),重组相邻帧的操作执行顺序(如图7(b)),同时结合计算密集型和内存密集型操作,优化流水线以提高硬件效率并减少延迟。
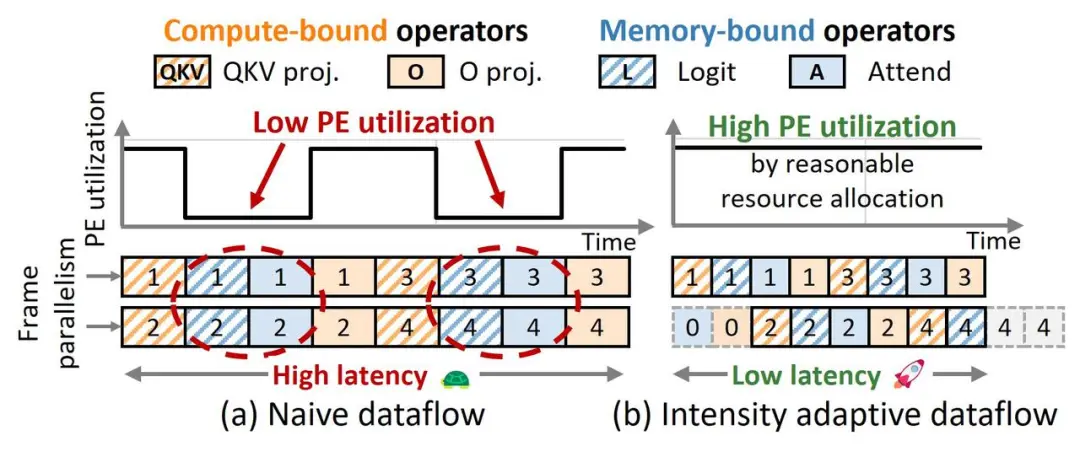
图 7:基于可重构架构的计算强度自适应数据流
计算强度自适应架构:
为支持强度自适应数据流优化,我们设计了一种可重配置硬件架构,其中路由控制器作为核心组件,用于动态调整处理单元(PE)与内存单元(ME)之间的数据路径(如图6(b)和6(e)所示)。路由控制器通过映射控制器动态分配资源,结合路由开关调整连接路径,并利用FIFO队列临时存储数据,以适应不同算子的资源需求。
07 评估
实验设置
基线
1. 通用架构:Intel Xeon 8358P CPU和NVIDIA A100 GPU。
2. 定制加速器:ViTCoD、InterArch和CMC三个SOTA视觉加速器。
算法设置
我们使用多个开源VDiT模型(包括Open-Sora、Latte等模型)来验证ViDA的有效性,选择FVD, FID和CLIPSIM作为评价指标,在UCF-101和MSR-VTT数据集上进行了测试。
算法评估
我们将ViDA的差分方法与InterArch和CMC两种代表性方法的准确性进行了比较。为确保实验的公平性,我们对InterArch进行了调整,使其同样考虑帧内相似性。我们首先基于OpenSora的基准MSR-VTT及UCF-101示例进行了精度测试,实验结果显示,在三个评价指标下ViDA的算法精度损失平均仅为0.40%,低于InterArch的0.57%和CMC的0.78%。通过进一步基于UCF-101数据集对OpenSora及Latte模型进行评估,ViDA的平均精度损失为0.81%,低于目前SOTA的工作CMC的1.11%。
性能评估
图 8展示了ViDA与不同基线的性能表现。与A100 GPU相比,ViDA实现了16.44倍的性能提升;相较于ViTCoD、InterArch和CMC,加速比分别提升了2.48倍、2.39倍和2.18倍。这一显著的性能提升主要得益于通过差分计算来同时计算Act-W和Act-Act算子,同时通过强度自适应数据流设计满足了长视频生成场景下对计算和存储资源的复杂需求。
此外,ViDA在面积效率方面的表现同样突出,其相较于A100 GPU提高了18.39倍;相较于ViTCoD、InterArch和CMC,几何平均效率分别提升了2.39倍、2.43倍和2.35倍。这主要得益于列聚集处理单元在列稠密模式下对稠密处理单元和稀疏处理单元的高效利用,以及精细化的任务分配策略在相同硬件面积下实现了更优的性能表现。
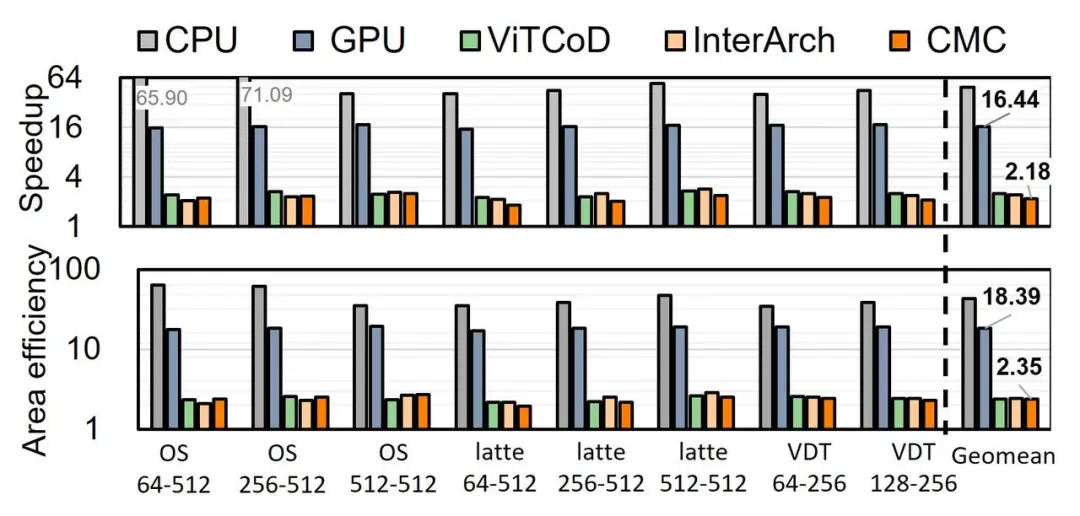
图 8:ViDA 与 CPU、GPU及SOTA加速器在三个 VDiT模型上的加速和面积效率比较
敏感性评估
参考帧选择的影响
如图9(a)所示,我们分析了参考帧选择对准确性和推理速度的影响。通过分析帧间余弦相似性,我们将每8帧分为一组。结果表明,参考帧选择对模型的CLIPSIM准确性几乎没有影响,同时加速比的变化也在可忽略范围内。
阈值选择的影响
如图9(b)所示,我们分析了不同分配阈值对处理单元数组负载和利用率的影响。结果表明,当阈值设为50%时,可以实现最低的负载和最高的硬件利用率。
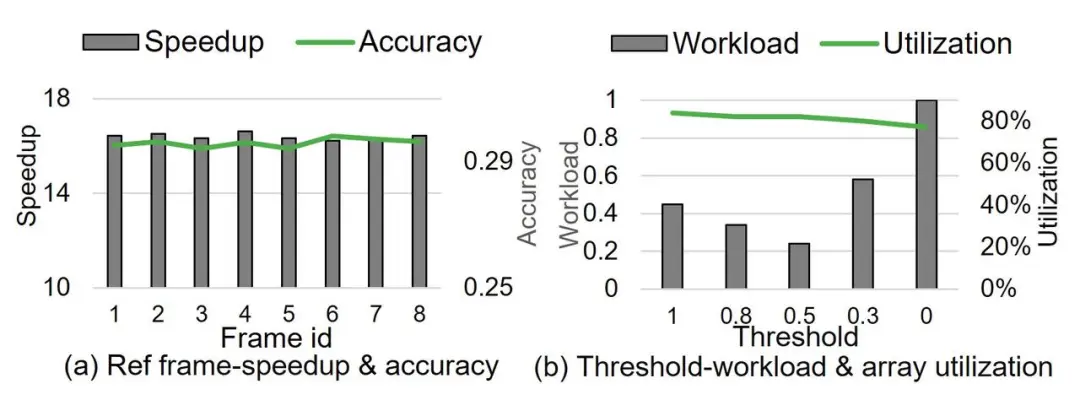
图 9:参考帧及阈值的选择对实验结果的影响
ViDA在多种主流VDiT模型上的实验结果表明,与NVIDIA A100 GPU和现有最先进加速器相比,它分别实现了平均16.44倍/2.18倍的加速比和18.39倍/2.35倍的面积效率提升,可有效降低视频生成模型对计算资源的消耗,加速视频生成模型的推理过程,推动视频生成技术更好、更快、更大范围产业化落地。






